.png)
問題1-3
コメントに従ってプログラムを記述してみましょう。
下記、【実行結果】と同じ内容が出力されるようにしてください。
【実行結果】
65 65 A 130
【PrimitiveCastPractice.java】
public class PrimitiveCastPractice { public static void main(String[] args) { // short型の変数 s1 を宣言し、65 を代入してください。 // s1 の値を出力してください。 // byte型の変数 b を宣言し、変数 s1 の値を代入してください。 // b の値を出力してください。 // char型の変数 c を宣言し、変数 b の値を代入してください。 // c の値を出力してください。 // short型の変数 s2 を宣言し、変数 s1 と b を足した値を代入してください。 // s2 の値を出力してください。 } }
解答例
【PrimitiveCastPractice.java】
public class PrimitiveCastPractice { public static void main(String[] args) { // short型の変数 s1 を宣言し、65 を代入してください。 short s1 = 65; // s1 の値を出力してください。 System.out.println(s1); // byte型の変数 b を宣言し、変数 s1 の値を代入してください。 byte b = (byte)s1; // b の値を出力してください。 System.out.println(b); // char型の変数 c を宣言し、変数 b の値を代入してください。 char c = (char)b; // c の値を出力してください。 System.out.println(c); // short型の変数 s2 を宣言し、変数 s1 と b を足した値を代入してください。 short s2 = (short)(s1 + b); // s2 の値を出力してください。 System.out.println(s2); } }
解説
今回の問題では適切にキャストすれば良いという問題になっています。
なぜキャストしなければいけないのでしょうか。
基本データ型8種類のうち、boolean型を除く7種類はすべて数値扱いです。
そして、この7種類の型は、扱える数値の大きさによって次のような大小関係があります。
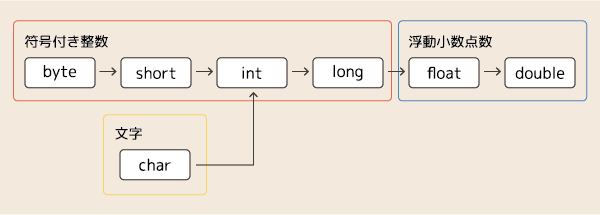
byte型からdouble型までが一連のラインとなっており、char型だけは少し特殊な扱いになっています。
char型のサイズはshort型と同じく2バイトなのですが、扱える数値の範囲が
short型は -32768 〜 32767
なのに対して、
char型は 0 〜 65535
となっています。(char型は負の数を扱えないのです)
最初にshort型の変数s1を宣言し、初期値65を代入しています。
次に、byte型の変数bを宣言し、変数s1の値を代入しようとしています。
先ほどの大小関係の図を見ると分かるように、大きい扱いであるshort型の変数に代入されている値を、小さい扱いであるbyte型の変数に代入しようとしているわけです。
これはbyte型がコップであり、short型がバケツと考えるとイメージが湧きやすいでしょう。
データの大きさはそれぞれに入る水の量と考えます。
「コップの水を、バケツに移しかえる」と考えても、何の心配も感じません。
実際にbyte型変数の値をshort型変数に代入しても、コンパイラは何のエラーも出力しません。
では「バケツの水を、コップに移しかえる」と考えるとどうでしょうか。
コップから水が大量にあふれ出るイメージが湧いてこないでしょうか。
コンパイラもその可能性を心配してしまいます。
ですので、short型の変数に代入されている値をキャスト無しでそのままbyte型の変数に代入しようとすると、コンパイラはエラーを出力するのです。
「コップから水があふれる」とは、プログラム的に言えば「データの欠落」が起きるということです。
コンパイラは少しでもその危険性があれば、コンパイルエラーを出すのです。
もしかしたら
「short型変数s1に入っている値は65だよね?
だったらbyte型の上限は127だから問題ないのでは?」
と思った人もいるでしょう。
ここで知っておいて欲しいポイントは
「コンパイラがチェックしているのは変数の型だけであり、変数の値は見ていない」
ということです。
コンパイルとは文法チェックをしているに過ぎません。
プログラムの実行結果で変数の値は動的に変換するわけですから、コンパイラはそこまでチェックすることができないのです。
そのため、プログラマはbyte b = (byte)s1;のようにキャストしなければいけないのです。
このキャストというのは、プログラマがコンパイラに対して「この代入は問題ないことを保障するから、コンパイルエラーにはしないで」と言っているのです。
ですので、もしデータが欠落してしまっても、それはすべてプログラマの責任になるのです。
しっかりと学習しているひとは、
「short型の変数に10を代入するのもダメなのでは?
整数リテラルの10ってint型扱いだよね。
short型の変数にint型の値は代入できないじゃん。」
こんな疑問が出たひとは素晴らしいですね。
確かに整数リテラルはint型扱いです。
しかし、byte型、short型、char型の変数には、その型で代入可能な範囲のリテラルであれば、そのまま代入可能という「特例」があるのです。
つまり、
byte b = 100; short s = 200; char c = 300;
という処理はOKなのです。
しかし、浮動小数点数リテラルにはこの特例がありません。
浮動小数点数リテラルはdouble型扱いになるため
float f = 3.14;
はコンパイルエラーになります。
どうすれば良いかというと、浮動小数点数リテラルの後ろに「F」(もしくは「f」)を付与します。
float f = 3.14F;
次に、char型の変数を確認します。
今回の問題ではchar型の変数cに対して、byte型の変数bの値を代入しようとしています。
先ほどの大小関係の図からすれば、より小さな扱いであるbyte型変数の値を、より大きい扱いであるchar型の変数に代入しようとしているわけですから、キャストは不要に感じます。
しかし、大小関係の図をよく見ると、int型からshort型とchar型の二手にラインが分かれています。
そしてbyte型はshort型のラインであり、char型とはラインが異なっています。
ラインが異なるbyte型とchar型には互換性がありません。
もちろん、short型とchar型にも互換性がありません。
原因としては、char型が負の値を扱えないからなのです。
この場合もプログラマがキャストして、処理内容を保障してあげる必要があるのです。
最後にshort型の変数s2の宣言について確認します。
ここでもキャストをしないとコンパイルエラーになってしまいますが、不思議に思った人はいないでしょうか。
「short型変数のbyte型変数を足し算しているということは、
異なる型同士の演算は大きな型の方に合わせられるよね。
ということは演算結果はshort型だから、short型変数に結果を代入するのは問題ないのでは?」
確かにそうなのですが、ここでもJavaの特例が出てきます。(ややこしいですね)
int型より小さい扱いの型(byte型、short型、char型)は、int型より小さい型の間で演算を行っても、自動的にint型に変換されてしまうのです。
その一例を見てみましょう。
byte b1 = 1; byte b2 = 2; byte b3 = b1 + b2; // ここでコンパイルエラーが発生 byte b4 = 1; byte b5 = -b4; // ここでコンパイルエラーが発生
「int型より小さい型の演算は常にキャストが必要ということか」
実はそうとも限らないのです。
例えばbyte型の変数bに対して、
b++; b += 1;
はコンパイルエラーになりません。
インクリメント・デクリメントといった単項演算子や算術代入演算子は自動的にダウンキャストを行ってくれるのです。
便利ですが、ちょっとややこしいですね。
Javaでは整数のデータ型にint型、浮動小数点数のデータ型にdouble型を使うのが一般的です。
そのため、今回の問題のようにbyte型、short型、char型とキャストで苦戦するというのは、実務レベルはほとんど無いかもしれません。
しかし、Javaの基本としてキャストはしっかりと理解しておきましょう。
参考図書
LINE公式アカウント
仕事が辛くてたまらない人生が、仕事が楽しくてたまらない人生に変わります。
【登録いただいた人全員に、無料キャリア相談プレゼント中!】

![]()