.png)
集合演算子
集合
リレーショナルデータベースでは、テーブルから欲しい情報だけを取り出したり、複数のテーブルを連付けて新しいデータを取り出したりすることができます。
テーブルに登録したデータの集まりを集合として考えます。
また集合からデータを取り出す際には、演算を行います。
集合は、次のような決まりに従って集められたデータです。
- 同一のデータは存在しない(重複がない)
集合の中に含まれる1つ1つの値を、要素といいます。
1つの集合には、要素を重複して入れることはできません。
同様にテーブルには、原則として重複したデータを登録できないようになっていますが、場合によっては運用上、重複データが必要になることもあり得るので、テーブルは重複データを許可する設計になっています。
重複データを登録できないようするには、主キーやUNIQUE制約を利用します。
- 集合内の要素に順番はない
集合には、順番という考え方がありません。
下図の「フルーツ」という集合には、「りんご」「みかん」といった要素がばらばらに入っています。
テーブルも同様です。
テーブルは表形式になっているので、登録順にデータが並んでいるように見えますが、データベース内では実際にはレコードは順番を持っていないのです。
しかし、登録したデータを利用する場合には、何らかの基準で並べられていた方がわかりやすいため、リレーショナルデータベースではインデックス機能を使っています。
集合演算
集合演算とは、2つの集合から新しい集合を取り出す演算です。
テーブルも同様で、演算を実行することで複数のテーブルから新しいデータを取り出すことができます。
集合演算には和演算、差演算、積演算、直積演算の4種類があります。
- 和演算
2つの集合を足す演算です。
例えば、集合Aと集合Bがあった場合、2つの集合に含まれる要素を重複を除いて集めます。
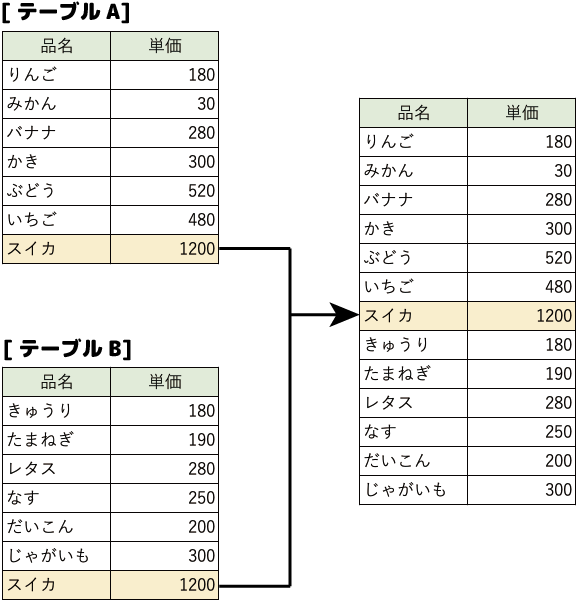
和演算を利用すると、別々のテーブルのデータを1つにまとめることができます。
この時、両方のテーブルに同じレコードがある場合には一方が削除されます。
リレーショナルデータベースでは、重複データを許可しないからです。
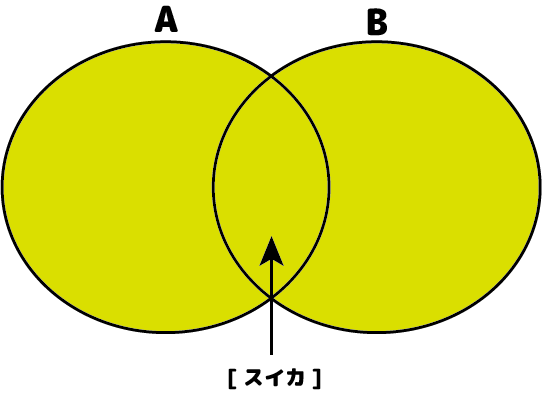
上の図では、「スイカ」のデータが1つのテーブルになった時、1つだけ登録されていることがわかります。
- 差演算
2つの集合の差をとりだす演算です。
2つのテーブルの差分を取り出します。
両方のテーブルに共通するレコードは除外されます。
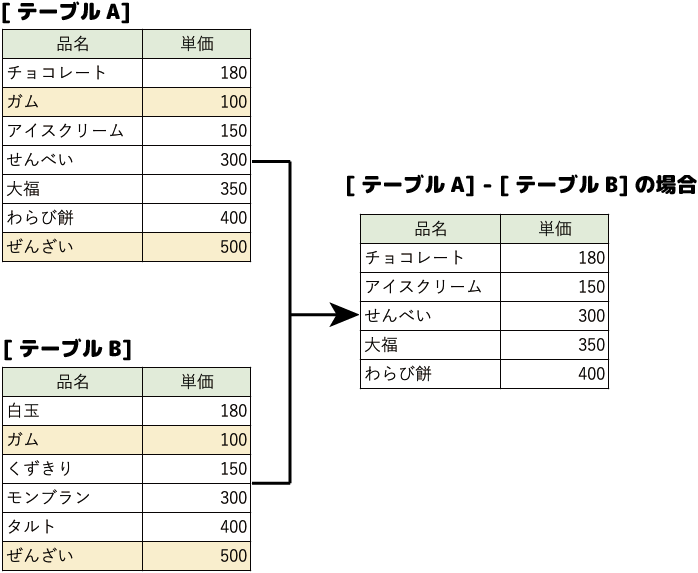
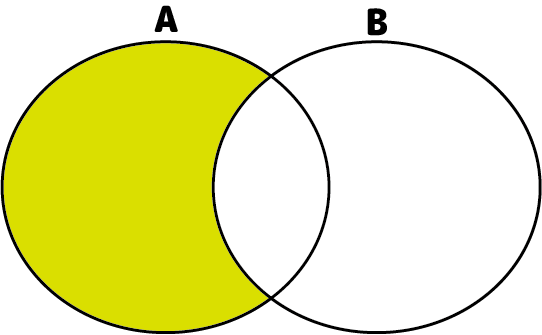
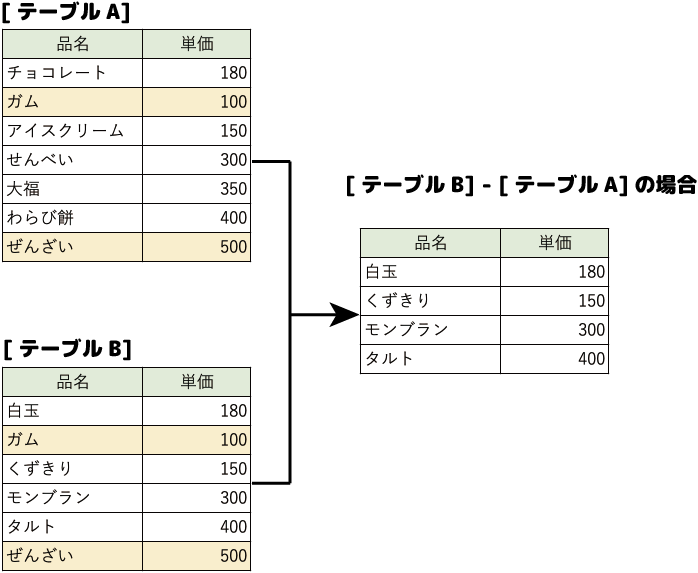
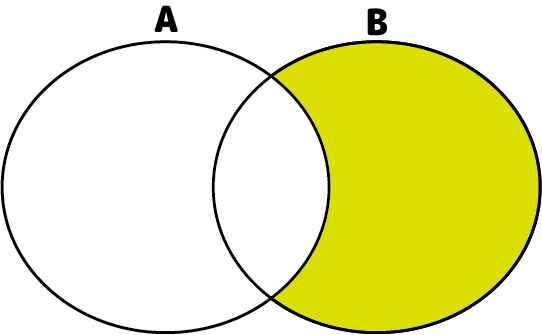
上の2つの図で示したように、[A]-[B]と[B]-[A]では結果が異なります。
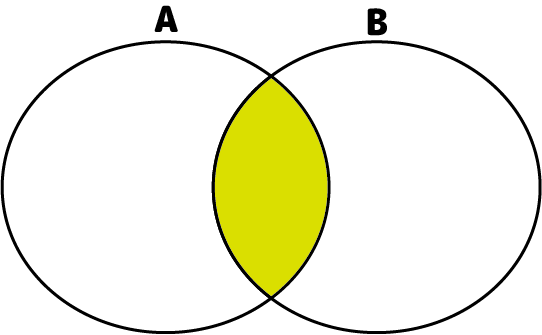
- 積演算
2つの集合の共通部分を取り出す演算です。
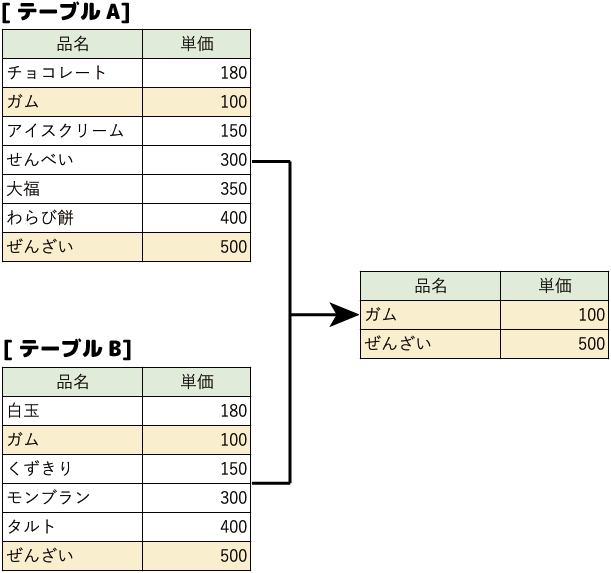
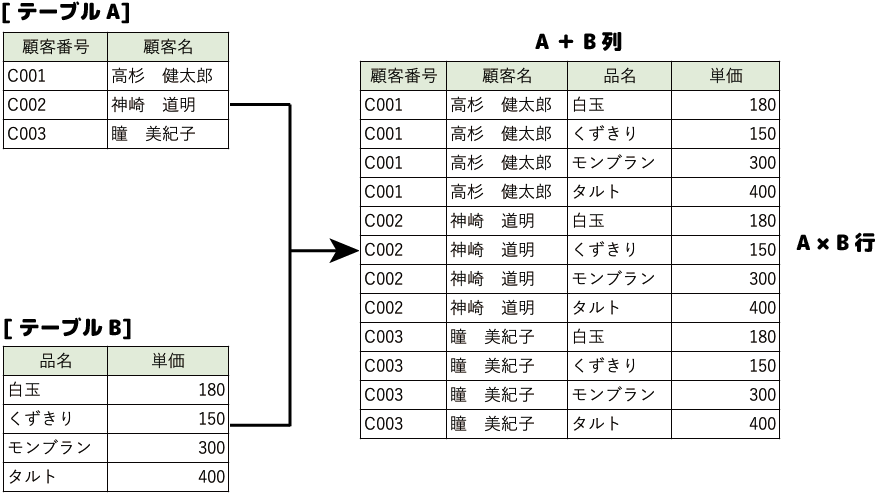
- 直積演算
2つの集合の要素を1つずつ取り出して、そのすべての組み合わせを作る演算です。
和演算、差演算、積演算は2つのテーブルの構造が同じ(列名と数が同じ)でなければなりませんでしたが、直積演算は構造の異なるテーブル(列名や数が異なる)を使うことができます。
直積演算を実行すると、列数は「テーブルAの列数+テーブルBの列数」、行数は「テーブルAの行数×テーブルBの行数」になります。
関係演算
関係演算は、リレーショナルデータベース専用の演算です。
選択演算、射影演算、結合演算、商演算があります。
商演算はあまり使われませんので、ここでの説明は省略します。
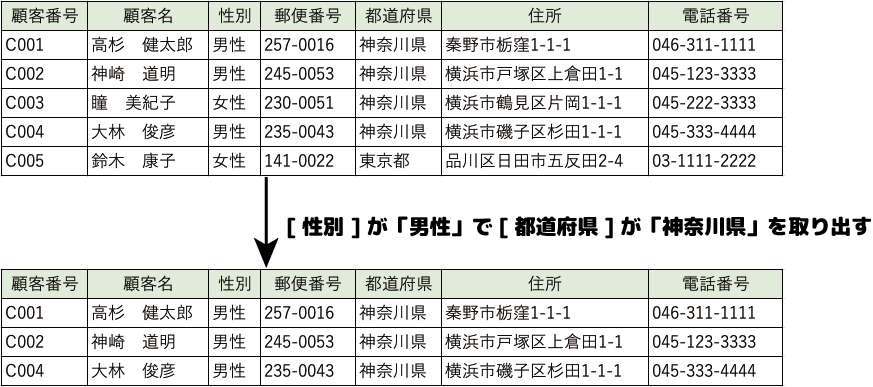
- 選択演算
指定した条件を満たすレコードを取り出す演算です。
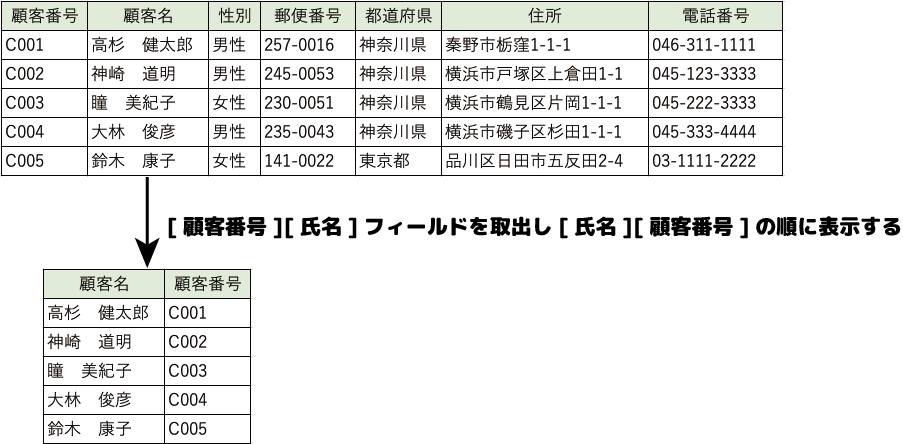
- 射影演算
必要なフィールド名を指定した順番で取り出す演算です。
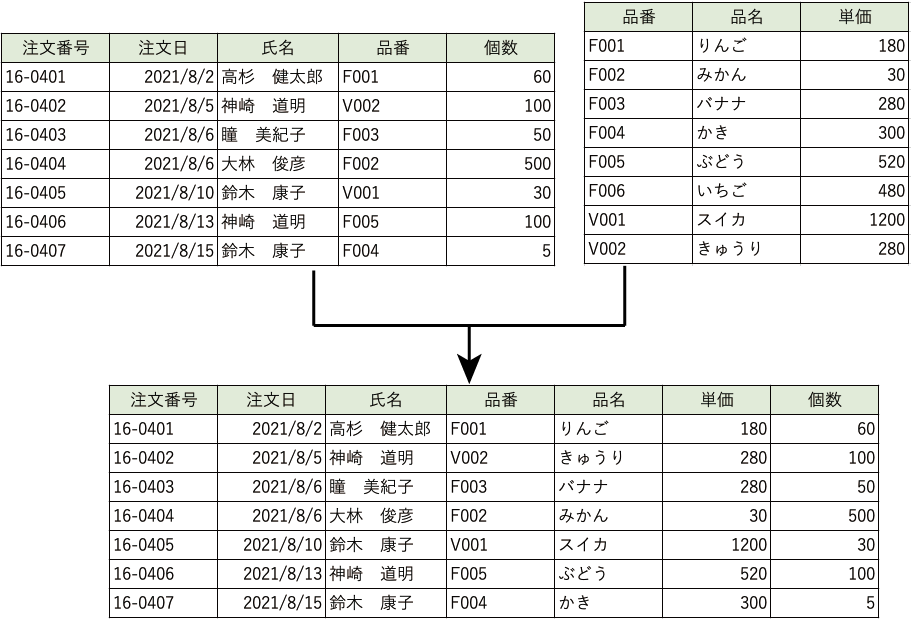
- 結合演算
共通するフィールドを使って2つのテーブルを結合し、新しいレコードの集まりを取り出します。
両方のテーブルで結合フィールドの値が等しいものを取り出します。
ビュー
ビューとは、実体を持たない仮想のテーブルです。
データベースを作る目的は、大量のデータを登録しておき、必要に応じて取り出し、利用することですが、欲しいデータごとにテ ーブルを作るのは大変な手間ですし、「1つのデータは1か所で管理する」というデータベースの大原則に反します。
そこで、データベースに対する様々な要求に応えられるように、登録されているデータの見せ方を定義します。
これがビューです。
ビューは、取り出されたデータをメモリ上で見せているだけで、実際のテーブルではありません。
リレーショナルデータベースで演算を行うというのは、実際にはSQLの命令を送ることです。
SQL命令で実行された結果はメモリ上に集められ、ユーザが見られるように表示をしてくれますが、メモリ上のデータはシステムが終了すると消えてしまいます。
毎回同じ条件でデータを抽出した結果が欲しいとき、毎回SQL命令を送るのもRDBMSにとっては負荷がかかります。
そこで、ビューを定義しておけば、もっと簡単な命令で同じ結果を得ることができます。
皆さんは、Microsoft Accessのクエリを使ったことがあるでしょうか。
実は、Microsoft Accessのクエリもビューと同じ役割を果たしており、テーブルに登録されているレコードの見せ方を定義しているだけで、それ自体が実際のデータを持っているわけではありません。
テーブルの結合によりSQLが複雑化することを避けるために、よく利用するテーブルは、あらかじめ結合された状態で疑似的なテーブルとして利用するわけです。
ビューを使うとあたかも1つのテーブルのように扱うことができますが、ビュー自体がデータを持っているわけではないので、ビューに対して検索が行われると自動的にビューの元になっているテーブルから実際のデータの抽出を行います。
ビューは、テーブルからさまざまな条件に合わせて作成することができますが、使い方を誤ると、ビューが増えすぎて煩雑になり、かえってどれを使っていいのかわからなくなってしまいます。
それぞれのビューは、何のために使うのかをきちんと整理しておく必要があります。
また、ビューを使うメリットとして、テーブルの結合だけではなく、演算の結果の仮想列を実在の列のように見せかけておくことや、表の一部だけを抜き出しておくこともでき ます。
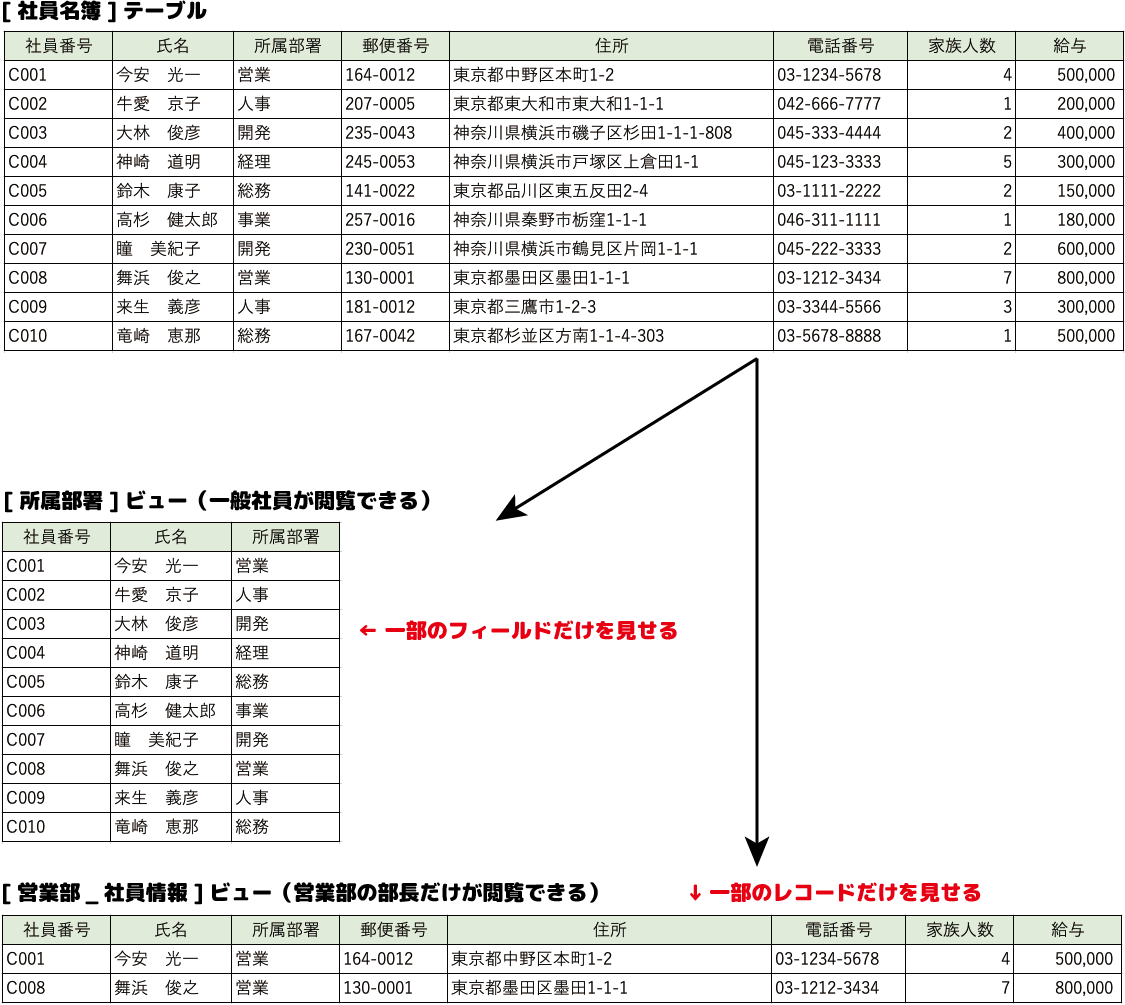
例えば、社員名簿があったとしましょう。
この社員名簿には住所、部署、家族構成、給与情報まで個人情報が載っているとしましょう。
すべての社員がこの情報を見ることができてしまっては問題がありますね。
このような時にビューを使うと、実際のテーブルを元にして「一般の社員が見るためのビュー」「人事部の社員だけが見られるビュー」といった形に情報を制限することができます。
表内のすべての列ではなく、閲覧してもよい列だけを抜き出して、あたかも表のように使えるようにする、これもビューの大切な役割になります。
参考図書
LINE公式アカウント
仕事が辛くてたまらない人生が、仕事が楽しくてたまらない人生に変わります。
【登録いただいた人全員に、無料キャリア相談プレゼント中!】

![]()