
.png)
Gitってどのようにデータを管理しているの?
前回の状態から新しいファイルを追加してその変更分をコミットした時はどのようなことが裏側でおこっているのでしょうか。
今回は「css/home.css」というCSSファイルを新規作成したとします。
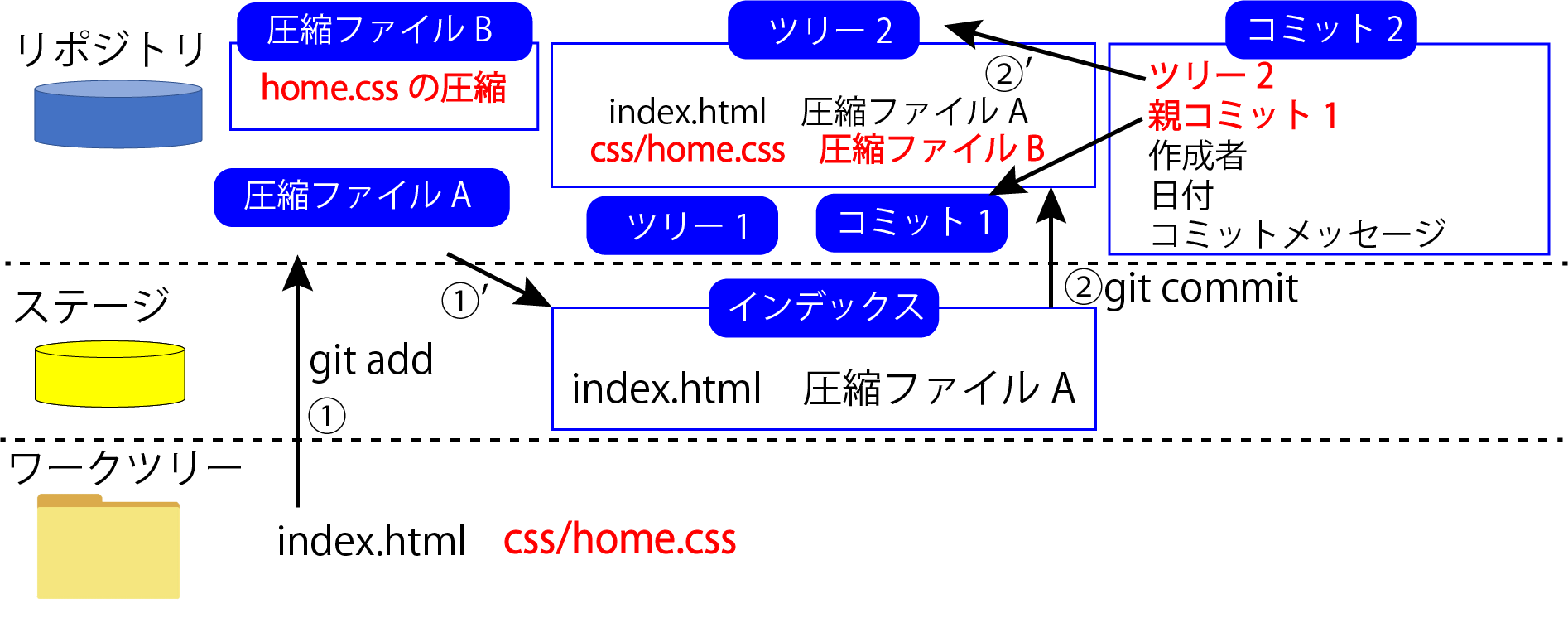
その「css/home.css」をステージに追加してみましょう。
ステージに追加する時はまず圧縮ファイルを作成します。
今回は「css/home.css」のファイルの中身を圧縮した「圧縮ファイルB」というファイルが作成されます。
次にインデックスに「圧縮ファイルB」は「css/home.css」だよというファイル構成を追記します。
これがステージに追加した時に起こっていることで、コマンドは「git add」です。
ではステージに追加できたので、コミットします。
コミットする際はまず、「ツリー2」というファイルを新規作成します。
「ツリー2」には今のステージの状態、つまりインデックスに記載されているファイル構成が保存されます。
ツリーを保存したら「コミット2」というコミットファイルを作成します。
「コミット2」にはまず「ツリー2」というツリー名が記録されます。
次に、ここが前回と違う点なのですが、親コミット情報として「コミット1」を親コミットとして記録します。
直前のコミットを自分の親コミットとして記録します。
これは何のためにしているのかというと、変更履歴をたどれるようにしています。
Gitのそもそもの役割はバージョン管理、つまり変更履歴が分かることでした。
コミットに直前のコミット名を記録しておけば、コミットが連鎖してたどれるようになるので、この仕組みで変更履歴をたどれるようにしているわけです。
親コミットを記録したら、後は前回と同じで「作成者」と「日付」と「コミットメッセージ」を記録します。
これはコミットした時に起こっていることで「git commit」コマンドでできます。
ちなみに、なぜインデックスとツリーというのが別ファイルなのでしょうか。
ほぼファイルの内容が同じなので一緒のファイルでも良いような気がしませんか。
これはなぜかというと、たくさんのファイルを変更していたときに「一部のファイルだけ先にコミットしたい」と言う時があったりします。
そういう時のために、コミットするファイルだけをまずステージに追加するようになっています。
だとしたら、逆にステージに追加する度にツリーファイルを作成しちゃえば良いじゃ無いかと思われるかもしれません。
ただそれだと非常に非効率なのです。
ステージに追加してコミットせず何度もステージに追加だけされたとします。
もしそのたびにツリーファイルを作成していると使わない無駄ファイルが量産されてしまうのです。
なので、ステージに追加した時はインデックスという一つのファイルに上書きしておいて、コミットする時だけちゃんと記録するときだけツリーというファイルに保存しておくようになっています。
ここまでで新規ファイルを追加した場合を見てきましたので、ファイルを変更した場合を見て行きます。
「index.html」のファイルに変更を加えたとします。
ではこの変更をステージに追加してみましょう。
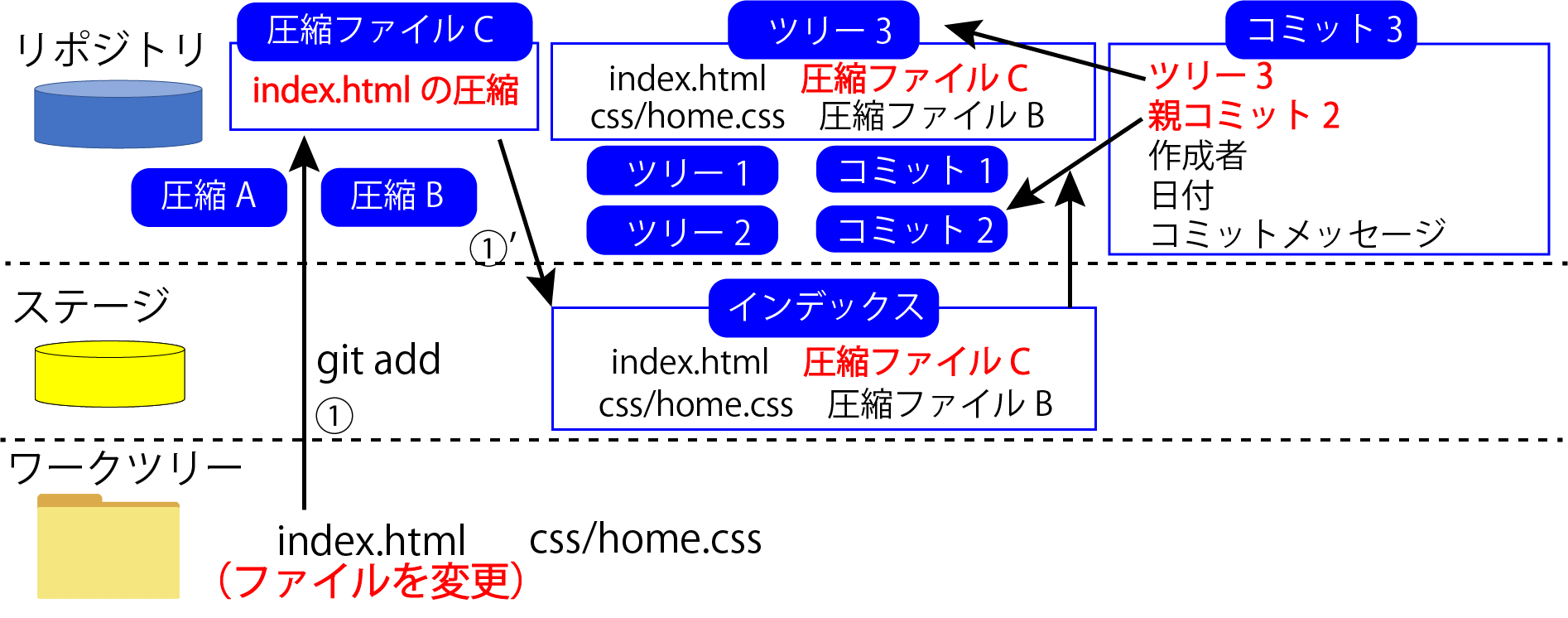
まず「index.html」の中身を圧縮した「圧縮ファイルC」を作ります。
この時圧縮ファイルが作られるのは「index.html」で「home.css」については作られません。
圧縮ファイルというのはファイルの中身が違う時だけ新しく圧縮ファイルが作られるようになっています。
なので、今回はファイルの中身を変更した「index.html」に対してだけ「圧縮ファイルC」が新たに作られています。
圧縮ファイルを作成したら、その情報をインデックスに追加します。
インデックスファイルの情報が「index.html」のファイルの中身は「圧縮ファイルA」だよと書かれていたところが、今回は「圧縮ファイルC」だよと書き換えられます。
ここまででステージに追加することができました。
ではここからはコミットしてみましょう。
まずツリーを作成します。
インデックスの内容を元に「ツリー3」という新しいツリーファイルを作成します。
ツリーファイルを作成したら「コミット3」というコミットファイルを新しく作成します。
「コミット3」には、ツリーが「ツリー3」、親コミットが「コミット2」、後は「作成者」「日付」「コミットメッセージ」が記録されています。
「コミット3」が「ツリー3」を指していて「ツリー3」が「ファイル名」と「ファイルの内容」を指しているので、「コミット3」を見れば「コミット3」の時のスナップショットが分かるようになっています。
また、親コミットとして「コミット2」を指しているので、「コミット3」と「コミット2」のスナップショットを比較すれば前のコミットからの変更差分も分かります。
ここまででコミットの完成です。
まとめ
では最後にGitのデータ構造のまとめ、振り返りをしていきます。
Gitはリポジトリに「圧縮ファイル」「ツリー」「コミット」ファイルを作成することでデータを保存しています。
ステージに追加する時に「圧縮ファイル」が作られ、コミットする時に「ツリー」と「コミット」が作られます。
その中のコミットが親コミットへの参照を持つことで変更履歴をたどることが出来るようになっています。
こういったデータ構造から分かることは、Gitの本質はデータを圧縮してスナップショットで保存しているということです。
Gitはコミットする前に何をやっているかというと、一つ目が圧縮ファイルを作成すること。
つまりデータを圧縮していました。
2つめがツリーファイルとコミットファイルを作成すること。
この2つがあることでその時点でのスナップショットが分かります。
このようにGitがやっていることの一番の根っこにあるのは、データを圧縮してスナップショットで保存することだったのです。
これを踏まえるとGitのコマンドというのは、そのデータ構造に対して色々な操作をしたり、その操作を簡単にできるようにコマンドが作られているということです。
次の解説からGitのコマンドを見ていきますが、今回見てきたデータ構造に対してどのような操作をしているかというのをイメージするよう意識して見てください。
Gitが何をしているのかよくわからないという場合、大抵このデータ構造にどういった操作をしているのかがイメージ出来ていないケースが多いです。
逆にここがイメージ出来ればGitは怖い、何が起きているのか分からないとうことは無くなります。
参考図書
独学で挫折しそうになったら、オンラインプログラミングスクール
