.png)
Gitってどのようにデータを管理しているの?
Gitがどのようにデータを管理しているのか、Gitのデータの持ち方について学びます。
Gitのデータ構造ってどのようになっているでしょうか。
Gitがなんで分かりにくいかというと、一番の原因はコマンドの裏で何が起こっているかが分からないからだと思います。
それは突き詰めていくとGitがどのようにデータを管理しているのか、履歴を保存した時に何が起こっているのかが分かっていないということです。
今回はGitのデータの管理のしかた、データ構造について学んでいくことで、コマンドの裏側でなにが起こっているか、そのベールを脱がしていきます。
今回の内容をしっかりと理解すれば、Gitのコマンドの理解が楽になります。
ではまず前回の復習からやっていきます。
前回ローカルは「ワークツリー」「ステージ」「リポジトリ」に分かれていることを見てきました。
まず用語の復習で、ワークツリーというのが作業場のことで、ステージというのはコミットする変更を準備する場所、リポジトリというのがスナップショットを記録する場所のことでした。
それで一連の作業の流れとしては、ワークツリーでファイルを変更して、その変更をステージに追加します。
そして、ステージに追加された変更分について、リポジトリをスナップショットとして記録します。
と言うのが一連の流れです。
ではステージに追加するときや、リポジトリに記録する時に、実際裏側では何が起きているのでしょうか。
一番始めに補足で、今回の内容はイメージを伝える事を優先しているので、厳密には正確ではないものになっています。
イメージを持っておくことが大事なので、そこの点はご了承ください。
まず「index.html」というファイルを新しく作ったと想定します。
このファイルをステージに追加していくとで、その裏側で何が起こっているかを見て行きます。
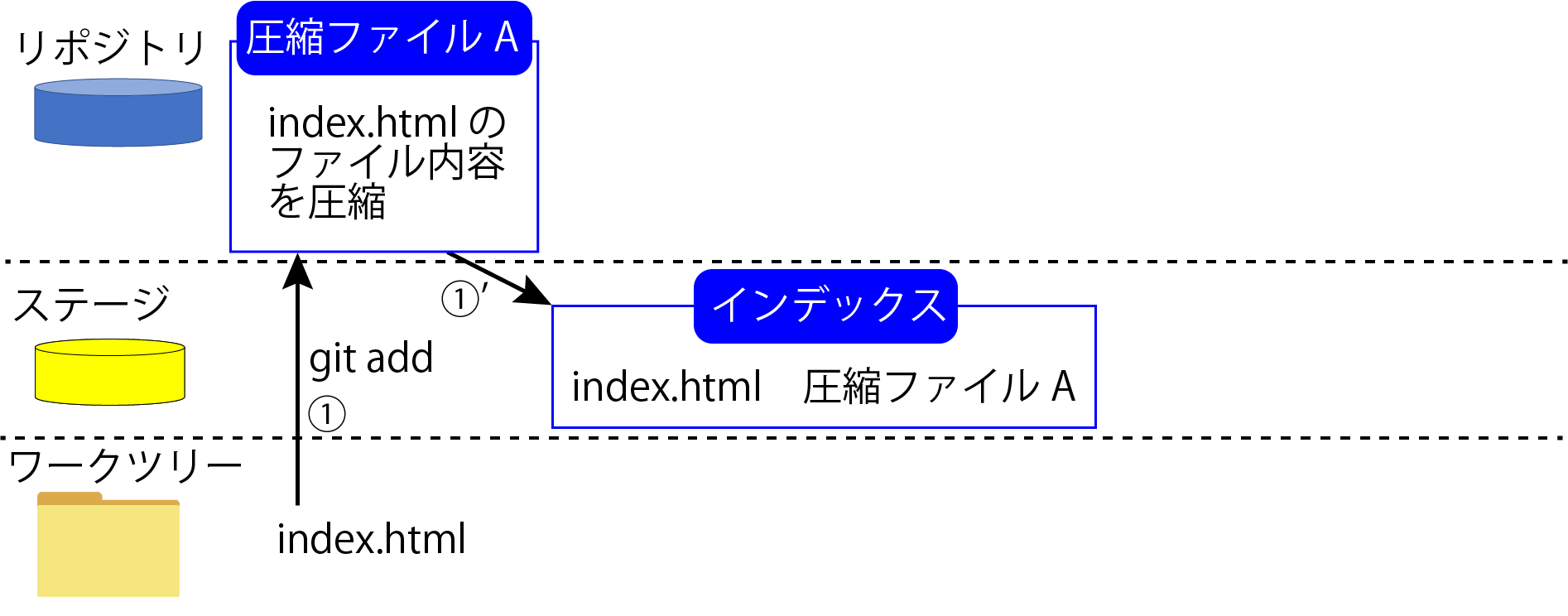
ステージに追加する時はまず「index.html」のファイルの中身を圧縮した「圧縮ファイルA」というファイルをリポジトリに保存します。
実際は圧縮ファイルという名前ではなくファイルの中身にヘッダーを付け加えた文字列をハッシュ関数で暗号化した文字列がファイル名になるのですが、今回は「圧縮ファイルA」というファイル名だと便宜的にしておきます。
「圧縮ファイルA」ができたら、今度はインデックスというファイルに『「index.html」という中身は「圧縮ファイルA」だ』というファイル名とファイルの中身をマッピングした情報を保存して行きます。(上図①)
ファイルの中身をまず圧縮して、次にインデックスのファイル名にマッピング情報を記載すると言うのがステージに追加する時に裏側で起こっていることです。(上図①')
ちなみにこれを実行しているのが「git add」というコマンドです。
ではステージには追加できたので、次にコミットする裏側でなにが起こっているのかを見て行きます。
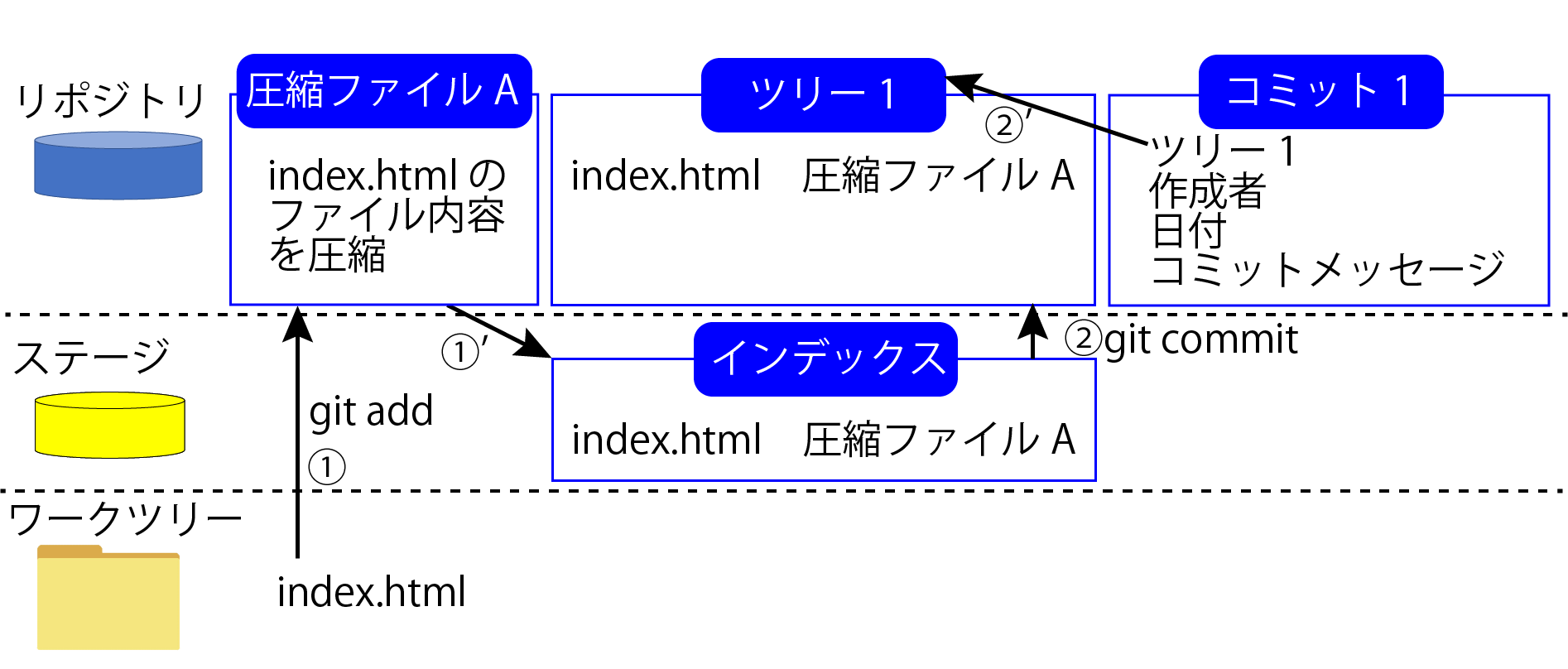
コミットするとインデックスのファイル構成を元に、「ツリー1」というファイルが作られます。(上図②)
「ツリー1」はインデックスに記載されているディレクトリのファイル構成を改めて保存した物です。
(因みにディレクトリというのはフォルダのことです。)
何でツリーというかと言うと、ディレクトリの構造を見た時にディレクトリというのは階層が深くなっていくほど、木の枝葉のように広がって行くので、そこからツリーとよばれています。
「ツリー1」というファイルを作ったら、次は「コミット1」と言うファイルを作って行きます。
「コミット1」にはいくつか情報が記載されています。
1つめが「ツリー1」というツリーのファイル名です。
2つめが「作成者」、コミットした人の名前とその人のメールアドレスです。
これはGitの初期設定で登録したユーザー名とメールアドレスが記録されます。
3つめが「コミットした時の日付と時刻」。
最後に「コミットメッセージ」が記録されます。
コミットメッセージというのは、コミットする時に何のためにその変更をしたのかというメッセージを残す仕組みになっていて、その内容です。
では何のためにこのような内容を記録しているのでしょうか。
まず、「ツリー1」からファイル構成、つまり、ファイル名とそのファイル内容が分かるのでコミットした時のスナップショットが分かるようになっています。(上図②')
あとは、「作成者」から誰が、「日付」からいつ、そして「コミットメッセージ」から何のために変更したのかが分かります。
まとめると、「コミット1」というファイルからその時のファイル状態と誰がいつ何のために変更したのかが分かります。
ちなみに「ツリー1」と「コミット1」と言うファイルを作るのが「git commit」というコマンドです。
これがステージに追加してコミットした時に裏側で起こっていることです。
まとめ
ではここまでを一旦振り返って見ましょう。
まず、「index.html」というファイルがありました。
それをまずステージに追加していきます。
ステージに追加する時は「圧縮ファイルA」というファイルの中身を圧縮したファイルを作成します。
次に「インデックス」というファイルに「圧縮ファイルAはindex.htmlというファイル名だよ」というファイル構成を記録していきます。
これがステージに追加する時に実際に起こっていることです。
ステージに追加できたら、コミットしていきます。
コミットの時はインデックスのファイルの内容を元に、まず「ツリー1」というファイル構成を表したファイルを作成します。
「ツリー1」が作成出来たら、「コミット1」というファイルを作成します。
「コミット1」にはコミットした時のツリーの情報とコミットした人、日付、コミットメッセージが記録されています。
そのため、その時のスナップショットと誰がいつ何のために変更したのかと言う事が分かるようになっています。
ではここでリポジトリを良く見てください。
リポジトリには「圧縮ファイルA」「ツリー1」「コミット1」という3つのファイルが保存されています。
gitはステージに追加してコミットする際、実際は圧縮ファイルとツリーとコミットという3種類のファイルを作成してデータを保存しているのです。
参考図書
独学で挫折しそうになったら、オンラインプログラミングスクール
