.png)
テーブル内の制約
データベースでは、データベース内のデータを正常に保つために、制約と呼ばれる仕組みが用意されています。
制約を正しく設定することにより、ユーザからのデータ更新の際に発生する登録ミスを防ぐことができます。
制約が守られていないとRDBMSがエラーを返すので、私たちは制約の内容をよく理解して、適切な制約を正しく設定する必要があります。
制約には次のようなものがあります。
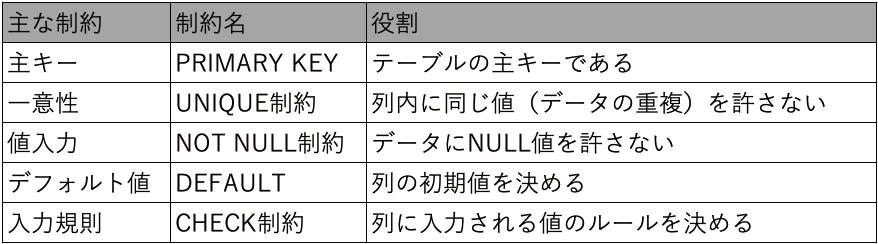
主キー(PRIMARY KEY)
リレーショナルデータベースの最大の特徴は、テーブルとテーブルを関連付けて管理することです。
下記の例では、商品リストテーブルの商品番号フィールドに主キーを設定し、注文リストの商品番号と関連付けをしています。
主キーはテーブルに1つだけ設定できます。
どのフィールドを主キーにするかといった決まりはありませんが、通常は、
- 目的のレコードを識別できること
- 管理しやすい値であること
を基準に選びます。
商品リストの[通常価格]フィールドは同じ値が出てくるので、レコードを識別することはできません。
また、[商品名]フィールドは同じ値は出てきませんが、値が文字列です。
主キーは並べ替えや検索をするときにも使用されるので、このような文字列は管理しやすいとは言えません。
この場合、商品名ごとに1つずつ振られている[商品番号]が主キーとして一番管理しやすいフィールドです。
また、1つのフィールドの値だけは識別できないような場合は、複数のフィールドの値を組み合わせると、レコードの識別ができるようになります。
例えば、住所録データにおいて、同じ住所に住む家族を識別するには「住所」と「名前」や「電話番号」と「名前」のように組み合わせることで、住所や電話番号は同じでも名前が異なっていれば、別人とみなすことができます。
このように、複数のフィールドを組み合わせたものを主キーとして利用することができます。
これを、複合主キーといいます。
主キーに適用されるルール
主キーは、テーブルに登録したデータを識別するための重要な情報です。
したがって、主キーになるフィールドに不正な値が登録されないように、次のルールが自動的に適用されます。
- すでに登録した値と同じ値は入力できない
- フィールドには必ず値を入力しなければならない
これらのルールが守られているかどうかは、RDBMSが監視をしています。
- 一意性制約(UNIQUE制約)
一意性制約は、UNIQUE制約とも呼ばれます。
「UNIQUE」は「唯一の」という意味があり、この設定をしたフィールドには、同じ値(重複した値)の入力はできなくなります。
主キーフィールドには、この制約が設定されています。
この制約はデータの二重登録を防ぐことが目的ですが、氏名フィールドや住所フィールドに設定をしてし
まうと、同姓同名であったり、同じ住所に住んでいる人の登録ができなくなるので注意が必要です。
- 非NULL制約(NOT NULL制約)
フィールドに値が何も入力されていない状態を「NULL値」と言います。
NOT NULL制約は、「NULL値を許さない」と言う事ですから、値が必ず入力されていなければならない、という意味になります。
データベースでは、NULL値が入力されているとデータの抽出や計算に思わぬ結果が起きることがあります。
必要がない限りは、できるだけテーブル内にNULL値が入らないように気を付けましょう。
主キーには、この制約が自動的に設定されています。
主キーの目的はレコードを特定することですから、NULL値が入っていてはいけません。

- デフォルト値(DEFAULT)
フィールドに値が設定されなかった場合に、自動的に設定される既定値です。
デフォルト値は、正確には制約ではありませんが、テーブルに設定しておくルールとして重要な役割を持っています。
デフォルト値をあらかじめ特定の値にしておくことで、テーブル内にNULL値が入力されるのを防ぐことができます。
次の例は、[電話番号]フィールドにデフォルト値「登録なし」を設定し、値が登録されなかった場合は「登録なし」の値が入ることで、NULL値が入ることを防いでいます。

- 入力規則(チェック制約)
フィールドに入力されるデータに、値の範囲や書式を制限する時に使います。
制約の設定と同時に許可する値の条件を設定します。
例えば、[性別]フィールドには「男性」「女性」「不明」のみ入るようにする、日付を表す[月]フィールドには1〜12の値のみ入るといった具合です。
テーブルの関連付け
何度も言いますが、リレーショナルデータベースの最大の特徴は、テーブルとテーブルを関連付けて利用することです。
テーブルを関連付けるには、そのための規則に従ったテーブルでなければなりません。
主キーもその1つです。
もし、テーブルに主キーを設定するための適切なフィールドがなければ、『 新たに作成する 』ということも管理上、必要な手順になります。
2つのテーブルに関連付けを設定するには、2つのテーブルに共通する値を持つフィールドがなければなりません。
前の例の[商品リスト]テーブルの[商品番号]フィールドと[注文]リストの[商品番号]フィールドは共通するデータです。
また、[顧客リスト]テーブルの[顧客番号]フィールドと[注文]リストテーブルの[顧客番号]も共通するデータです。
[商品リスト]テーブルと[注文]リストテーブルは、[商品番号]という共通のフィールドで関連付けられます。
[顧客リスト]テーブルと[注文]リストテーブルは、[顧客番号]という共通のフィールドで関連付けられます。
このような関連付けを、リレーションシップ(Relationship)と言います。
リレーションシップには、次の3種類があります。
- 一対一(いちたいいち)
- 一対多(いちたいた)
- 多対多(たたいた)
この中で最もよく使われるのが「一対多」のリレーションシップです。
ここでは、一対多のリレーションシップを詳しく解説します。
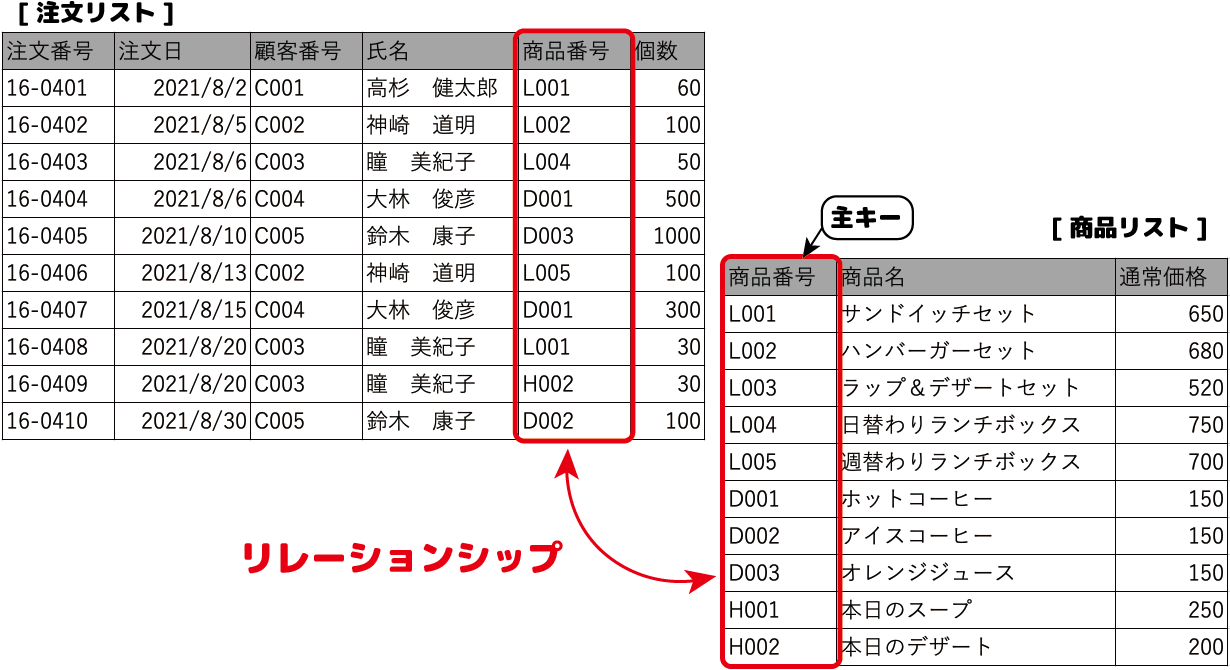
一対多のリレーションシップ
テーブルの1レコードが、もう一方のテーブルの複数のレコードに対応するリレーションシップです。
下の図では、[商品リスト]テーブルの1つの商品番号が[注文リスト]テーブルでは複数使われているので、[商品リ スト]テーブルが「一」側であり、[注文リスト]テーブルが「多」側になります。
2つのテーブルに共通するフィールドのうち、一側テーブルのフィールドを主キー、多側テーブルのフィールドを外部キーと言います。
リレーショナルデータベースの「1つの情報は1つのテーブルで管理する」というルールでは、まさにこの一対多のリレーションシップを使うことで、データを効率よく管理し、必要なデータを取り出しやすくしています。
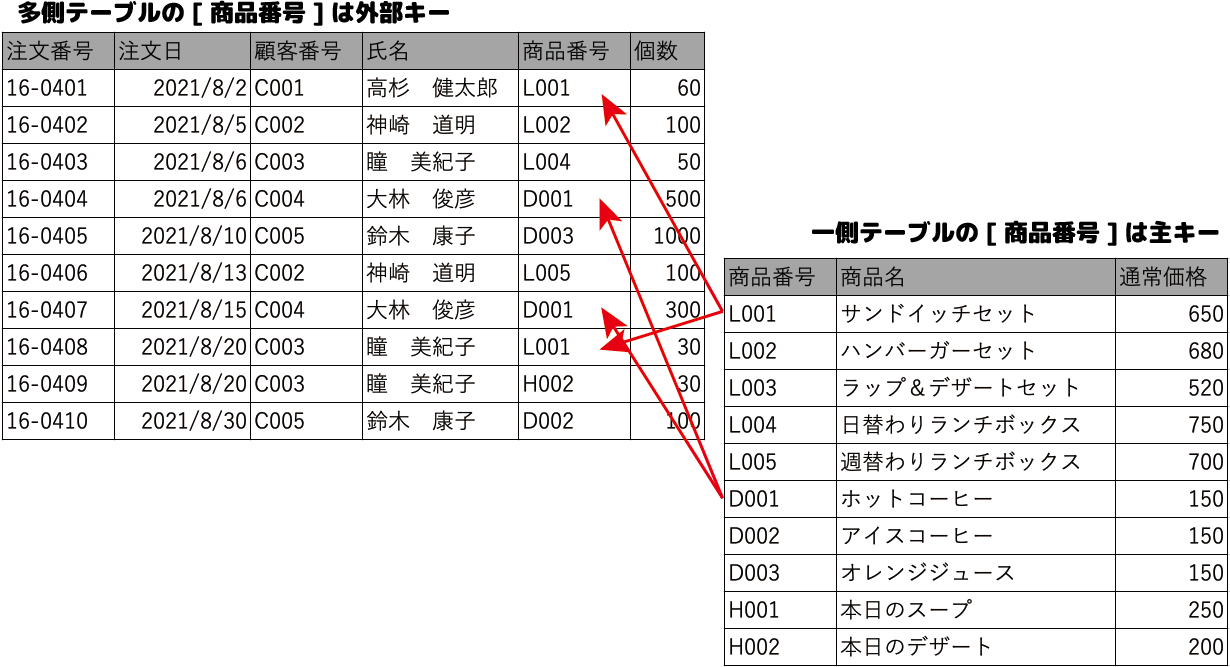
2つのテーブルでリレーションシップを設定するためには、次の条件がそろっている必要があります。
- 両方のテーブルに同じ値を保持するフィールドがあること
- 一方のテーブルに主キーが設定されていること
これまで見てきた[商品リスト]テーブルの[商品番号]フィールドと[注文リスト]テーブルの[商品番号]フィールドは、この2つの条件を満たしています。
一対多のリレーションシップを設定すると、2つのテーブル間でデータの矛盾が発生しないように次のルールが発生します。
このルールを、参照性制約または参照整合性制約と言います。
ルールに違反するとRDBMSがエラーを返します。
- 一側のテーブルに存在しない値は、多側のテーブルに登録できない
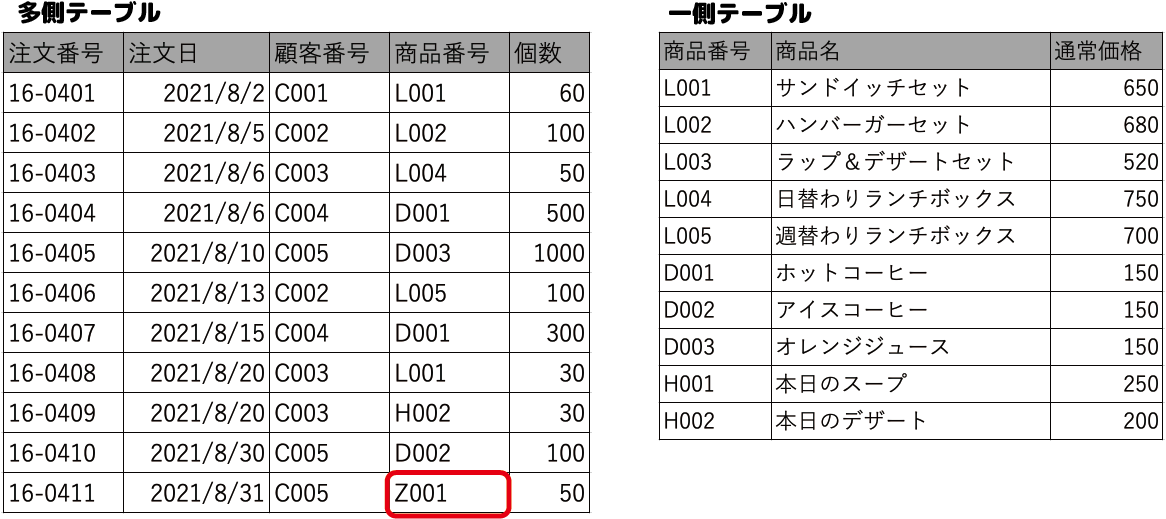
上の例では、多側の[商品番号]フィールドに「Z001」というデータを入力しようとしていますが、一側のテーブルの[商品番号]フィールドに「Z001」が登録されていないため、RDBMSはエラーを返し、そのデータの入力はできません。
これにより、[商品リスト]テーブルに存在しないデータは登録できなくなるので、不正なデータが入力さ
れるのを防ぐことができます。
- 多側のテーブルに存在する値は、その値を一側のテーブルで更新できない
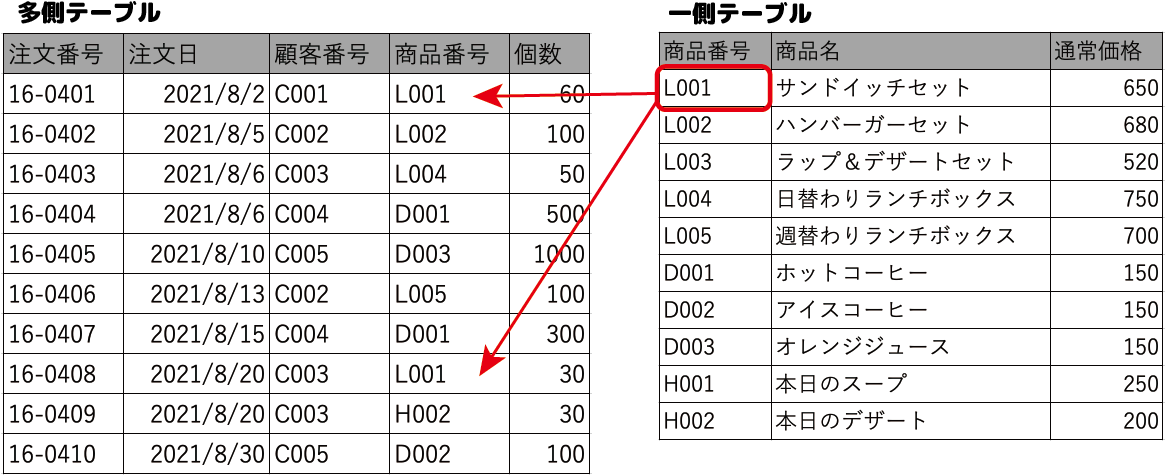
一側テーブルの[商品番号]フィールドの「L001」の値を他の値に変更しようとすると、多側のテーブル「L001」が使われているため、RDBMSはエラーを返し、データの変更ができません。
これも多側のテーブルに不正な値が入ることを防ぐためです。
- 多側のテーブルに存在する値は、一側のテーブルから削除できない
これも前のルールと同様、一側のデータを削除してしまうと、多側では該当する商品コードが見つからなくなってしまうためです。
ただし、リレーションシップを設定した場合でも、多側のテーブルにレコードがない場合は、それを一側のテーブルで更新したり、削除したりすることができます。
参照整合性 制約 のオプション
リレーションシップを設定した2つのテーブル間でデータの矛盾が発生しないように、次のオプションを付けることができます。
- 連鎖更新
一対多のリレーションシップが設定されている時、一側の主キーの値を更新した時、それに対応する多側の外部キーの値を更新します。
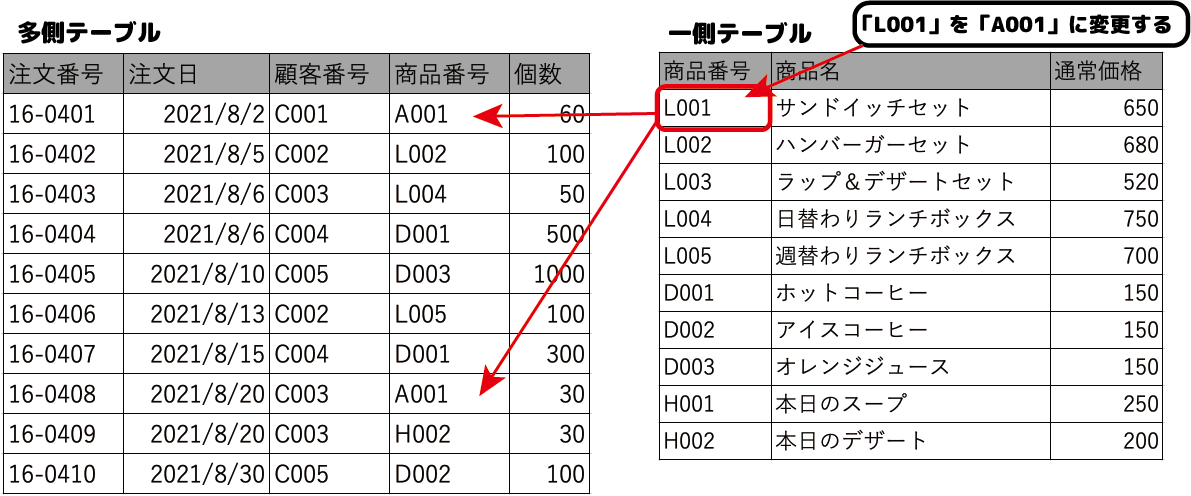
上の例では、一側の商品番号「L001」を「A001」に修正すると、多側テーブルの該当するレコードが自動的に更新されます。
- 連鎖削除
一対多のリレーションシップが設定されている時、一側のレコードを削除した際に、それに関連する多側のレコードが自動的に削除されます。
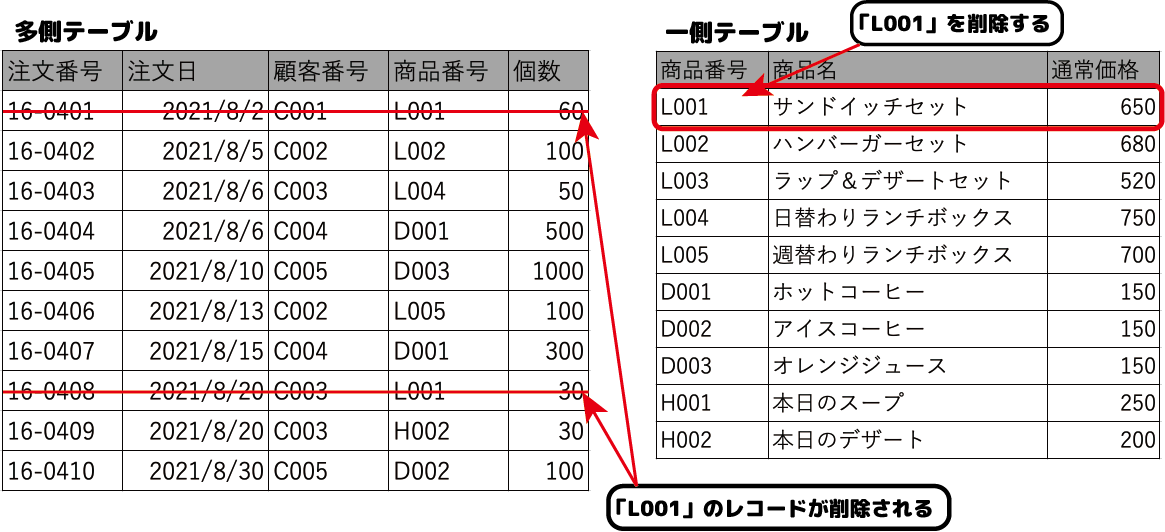
上の例では、一側の商品番号「L001」のレコードを削除しています。
すると多側の商品番号「L001」のレコードが自動的に削除されます。
- インデックス
インデックスは制約ではないのですが、登録したレコードを効率よく検索するために設定します。
主キーと混同されやすいのですが、主キーの役割は「テーブルに登録されたレコードを識別する」ものでした。
インデックスは、検索のパフォーマンスを上げる役割を果たします。
本の巻末に「索引」がついていることがありますね。
これを利用すると1ページずつ読まなくても、必要な情報を素早く見つけられます。
データベースのインデックスもこれと同じような役割を果たします。
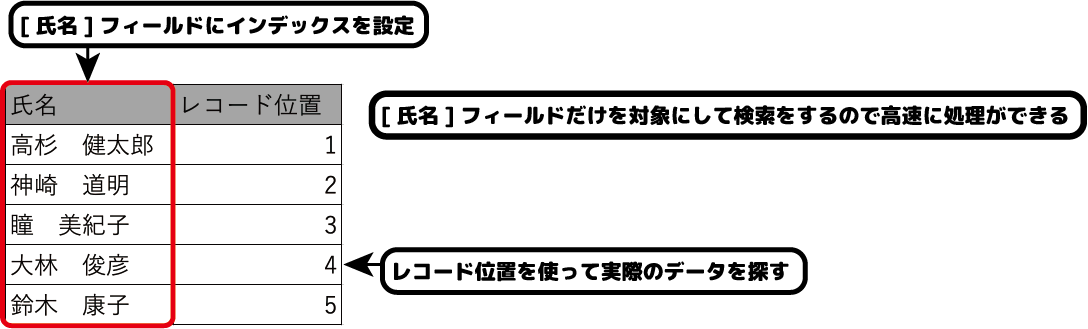
例えば、[顧客リスト]から[氏名]が「大林 俊彦」のレコードを検索したいとします。
インデックスを使用しない検索ではすべてのデータが検索の対象となるため、1件目から順番に「大林 俊彦」を探していきます。
4件目に来た時にはじめて探していたデータが見つかります。
これでは見つかるまでに時間がかかってしまいます。
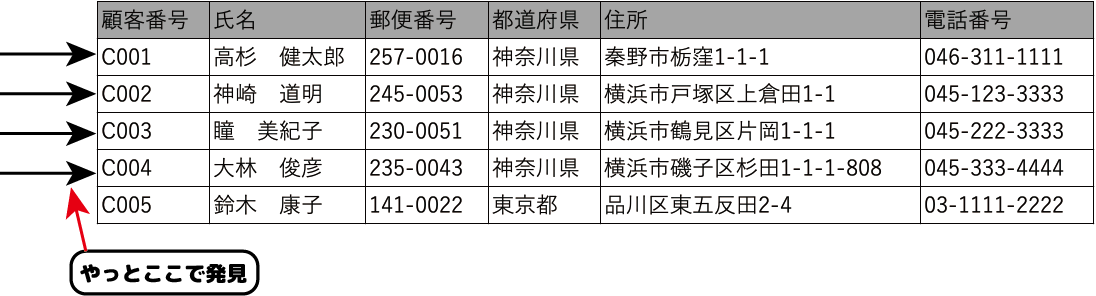
そこで、インデックスを検索条件に使われるフィールドに設定しておきます。
検索は、検索条件のフィールドだけを対象にするので、レコード全体を検索するより高速に処理を実行することができます。
インデックスを設定すると、実際のテーブルとは別にインデックステーブルが作成されます。
インデックステーブルには、検索条件ごとにテーブル内のどの位置にデータがあるかという情報が追加されます。
インデックスを使って見つかったレコードは、インデックステーブルに登録されたレコード位置をたどって実際のレコードを見つけ出します。
インデックスは、テーブルのあらゆるフィールドに対して作成できます。
ただし、むやみにインデックスを多くすると、データの書き込み、更新、削除の処理が遅くなってしまいます。
これらの処理が発生するたびに、インデックステーブルが更新されるからです。
さらに、インデックステーブルの分だけ、データのファイルのサイズが大きくなってしまうという問題もあります。
インデックスは、次のような場合に使うと効率的であるとされています。
- テーブルに大量のレコードが登録されている時
- 抽出の結果が元のレコード数の10〜15%である時
インデックスを使うか使わないかは、データベースを設計する上で考慮すべき項目の一つと言えます。
インデックスは、データの整合性を保つための主キーに自動的に設定されますが、主キーとインデックスは目的が違うことをしっかり押さえておきましょう。
参考図書
LINE公式アカウント
仕事が辛くてたまらない人生が、仕事が楽しくてたまらない人生に変わります。
【登録いただいた人全員に、無料キャリア相談プレゼント中!】

![]()