.png)
正規表現
文字列の検索や置換を行うとき、探したい文字列を直接指定するのではなく、特徴(パターン)を指定することで複数の異なる文字列を一括して扱うことができます。
この文字列の組み合わせ(パターン)の事を正規表現と言います。
そして文字列の中からパターンに合致するものを探し出すことをパターンマッチと言います。
また、パターンを作成する際に使用する特殊文字をメタ文字と言います。
メタ文字はパターンの一部分を特殊な記号であらわしたものです。
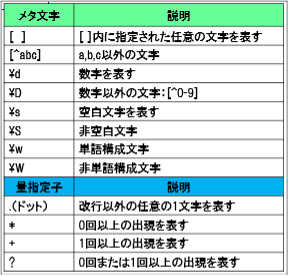
【主なメタ文字】
次の表はパターンマッチに使用される主なメタ文字です。
正規表現で使用するメタ文字の一部では¥記号を使用します。
データの一部の文字としての¥なのか、メタ文字の¥なのかを区別するためにもうひとつ、¥記号を頭につけます。
¥記号が2つ重なったものはデータの一部の¥という文字ではなく、メタ記号を表します。
この頭につける¥記号をエスケープシーケンス文字といいます。
また、正規表現には、量指定子というものがあり、前述の文字や数字が何回出現するかを指定することができます。
例えば、次の例を見てみましょう。
パターン「 a¥¥w+b 」、比較対象文字列 「aaaaaab」 → 一致(trueを返す)
「 a¥¥w+b 」というパターンでは、「a」で始まり、文字が1回以上出現し、「b」で終わることを表します。
この例では+という量指定子が、¥wの後ろに記述されているので、文字が1回以上出現することを表しています。
比較対象の文字列「aaaaaab」はaで始まりaという文字が5回続き、bで終わっているので、このパターンと一致しており、trueを返します。パターン「 a¥¥d+b 」、比較対象文字列 「a99999b」 → 一致(trueを返す)
「 a¥¥d+b 」は、「a」で始まり、数字が1回以上出現し、「b」で終わることを表します。
「a99999b」はaで始まり、数字の9が5回続き、bでおわっているので、このパターンと一致しています。パターン「 a¥¥s+b 」、比較対象文字列 「a b」 → 一致(trueを返す)
「a b」はaで始まり、空白が3回続き、bで終わっているので、このパターンと一致しています。
パターンマッチ
Javaで正規表現を使って文字列を検索するには、java.util.regexパッケージに含まれている下記のクラスを使用します。
【java.util.regexパッケージの正規表現に関する主なクラス】

正規表現を使ってデータを検索する(パターンマッチ)には次のようなメソッドを使用します。
【正規表現のメソッド】

正規表現を使って文字列を検索するには、次の2通りがあります。
- Patternクラスのmatches()メソッドを使って、正規表現に合致する文字列を一度だけ検索する
- 正規表現をコンパイル、保存をしておき、それを利用して何度も検索する
2を行う場合には次の手順を実行します。
(手順)
- Patternクラスのcompile( )を使用して正規表現を表すオブジェクト(Patternクラスのインスタンス)を生成する
- Patternクラスのmatcher( )を使用して正規表現エンジン(Matcherオブジェクト)を生成する
- Matcherクラスのmatches ( )を使用してパターンと比較する
- Matcherクラスのfind( )を使用してパターンと一致する部分を検索する
- Matcherクラスのメソッドを使用してパターンマッチの結果を取り出す→ start( )、group( )
【正規表現に合致する文字列を一度だけ検索する】
import java.util.regex.Pattern; class PatternSample1{ public static void main(String args[ ]){ System.out.println(Pattern.matches("a¥¥w+b","aaaaaab")); System.out.println(Pattern.matches("a¥¥d+b","a99999b")); System.out.println(Pattern.matches("a¥¥s+b","a b")); } }
実行結果
true true true
Patternクラスのstaticメソッドである、matches()メソッドを使って、パターンマッチングができます。
matches()メソッドの第1引数には、パターンを指定し、第2引数には比較対象の文字列を指定します。

4行目~6行目でパターンマッチを行い、パターンに合致した場合はtrueを、合致しない場合にはfalseを返します。
【正規表現に合致する文字列を何度も検索する】
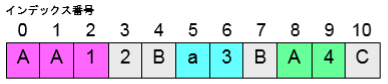
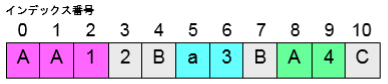
import java.util.regex.Matcher; import java.util.regex.Pattern; class PatternSample2{ public static void main(String args[ ]){ Pattern pattern1 = Pattern.compile("a¥¥d+b"); Matcher matcher1 = pattern1.matcher("aaaaaab"); System.out.println(matcher1.matches()); Matcher matcher2 = pattern1.matcher("a99999b"); System.out.println(matcher2.matches()); Pattern pattern2 = Pattern.compile("[Aa]+¥¥d"); Matcher matcher3 = pattern2.matcher("AA12Ba3BA4C"); while(matcher3.find()){ System.out.println("インデックス番号:" + matcher3.start( ) + ":" + matcher3.group( )); } } }
実行結果
false true インデックス番号:0:AA1 インデックス番号:5:a3 インデックス番号:8:Ar
Patternクラスのmatches( )を使用して検索する場合には、パターンをその都度指定をする必要があります。
何度も同じパターンの検索を行う場合には、パターンをコンパイルして保存しておくと、パターンマッチする際に再利用することができます。
5行目では、Patternクラスのcompile( )を使用して、引数に指定された正規表現のパターンからPatternクラスのインスタンスを作成します。
これが正規表現を表すオブジェクトになります。
6行目では、Patterクラスのmacher()を使用して、Mathcerクラスのインスタンスを生成します。
これが正規表現を使用してパターンマッチを行う正規表現エンジンと呼ばれるものになります。
7行目で、Matcherクラスのmatches()を使用して、パターンマッチを行います。
ここでは「aで始まり、1つ以上の数字が続いたあとbで終わる」パターンですが、比較対象の「aaaaaab」はこれに一致していないので、falseが返ります。
8行目~9行目も同様に5行目で作成した正規表現のパターンと比較するための正規表現エンジンであるMatchersオブジェクトを作成し、matches( )でパターンマッチを行っています。
9行目では、比較対象の「a99999b」は5行目のパターンと一致しているため、trueが返ります。
11行目では、「大文字のAまたは小文字のaで始まり1つ以上の数字が現れる」というパターンオブジェクトを生成しています。
12行目で11行目の正規表現のパターンと比較するための正規表現エンジンであるMatchersオブジェクトを作成します。
13行目~15行のwhile文では、Matchersクラスのfind()を使用して、パターンに一致していくものを先頭から検索していき、一致したものがあればtrueを返します。
14行目では、start()を使用すると、パターンが見つかったインデックス番号を取得することができ、 group()を使用すると、そのパターンと一致した文字列を取得することができます。
この例では、インデックス番号0から始まるAA1とインデックス番号5から始まるa3、インデックス番号8から始まるA4がパターンと一致します。
正規表現の活用
Stringクラスのsplit()メソッドは、対象となる文字列を、複数の文字列に分割することができます。
その際、split()メソッドの引数に正規表現を利用することができます。
Stringクラスのsplit()は引数に指定されたパターンに一致する位置で、文字列を分割して、String型の配列として返します。
【split()の引数に正規表現を利用する】
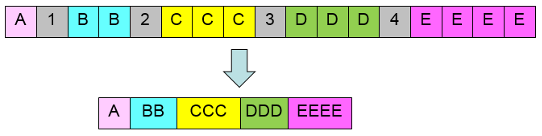
class PatternSample3{ public static void main(String args[]){ String str = "A1BB2CCC3DDD4EEEE"; String [ ] s = str.split("¥¥d"); for(int i = 0; i < s.length ; i++){ System.out.println(s[i]); } } }
実行結果
A BB CCC DDD EEEE
3行目で、String型のstr変数に文字列「A1BB2CCC3DDD4EEEE」を格納しておきます。
4行目で、split()の引数に¥dという正規表現のパターンを指定します。1つ目の¥記号は正規表現を表すエスケープシーケンス文字です。
¥dは数字1文字を表しますので、str変数に格納された文字列から、数字1文字が出てきたところで、分割をして、配列に格納します。
5行目~7行目で配列に格納された要素を、for文内で出力しています。
まとめ
正規表現
- 文字列の検索や置換を行うとき、特徴(パターン)を指定することで複数の異なる文字列を一括して扱います。
- 文字列の組み合わせ(パターン)の事を正規表現と言います。
- 文字列の中からパターンに合致するものを探し出すことをパターンマッチと言います。
- パターンを作成する際に使用する特殊文字をメタ文字と言います。
パターンマッチ
- Patternクラスのmatches()メソッドを使って、正規表現に合致する文字列を一度だけ検索します。
- 正規表現をコンパイル、保存をしておき、それを利用して何度も検索します。
正規表現の活用
- split()メソッドは、対象となる文字列を、複数の文字列に分割することができます。
LINE公式アカウント
仕事が辛くてたまらない人生が、仕事が楽しくてたまらない人生に変わります。
【登録いただいた人全員に、無料キャリア相談プレゼント中!】

![]()